文章目录
- 单机版环境搭建及相关DEMO
- Flume
- Kafka
- Spark
- Flume_Kafka_SparkStreaming实现词频统计
- 分布式环境搭建及相关DEMO
- 单机版环境搭建及相关DEMO
本文档主要讲述了flume+kafka+spark的单机分布式搭建,由浅入深,介绍了常见大数据流处理流程
单机版环境搭建及相关DEMO
Flume
Flume基本介绍与架构
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume出生日记
有很多的服务和系统
- network devices
- operating system
- web servers
- Applications
这些系统都会产生很多的日志,那么把这些日志拿出来,用来分析时非常有用的。
如何解决数据从其他的server上移动到Hadoop上?
shell cp hadoop集群上的机器上, hadoop fs -put …/ 直接拷贝日志,但是没办法监控,而cp的时效性也不好,容错负载均衡也没办法做
======>
Flume诞生了
Flume架构
Flume组成架构如图1-1,所示:
 图1-1 Flume组成架构
图1-1 Flume组成架构
Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的,是Flume数据传输的基本单元。
Agent主要有3个部分组成,Source、Channel、Sink。
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume拓扑结构
Flume的拓扑结构如图1-3、1-4、1-5和1-6所示:
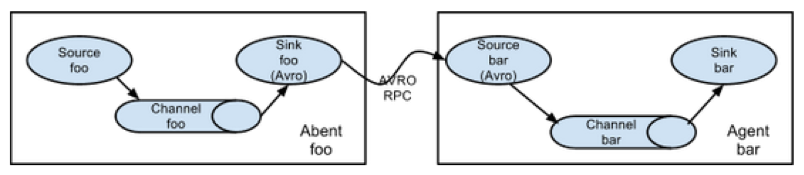
图1-3 Flume Agent连接

图1-4 单source,多channel、sink

图1-5 Flume负载均衡

图1-6 Flume Agent聚合
Flume安装部署
Flume的安装相对简单,但是前提是要先下好Java环境JDK,1.8以上即可,JDK安装可以查看Kafka安装流程,这里以Linux下的安装为例
Flume安装地址
安装部署
- 解压apache-flume-1.7.0-bin.tar.gz到/usr/local/目录下(安装包详见安装包文件夹flume文件夹下的tar.gz压缩包)
#把下载的包移动到目录
$ sudo mv apache-flume-1.7.0-bin.tar.gz /usr/local
#解压
$ sudo tar -zxvf apache-flume-1.7.0-bin.tar.gz /usr/local/
- 修改apache-flume-1.7.0-bin的名称为flume
$ sudo mv apache-flume-1.7.0-bin flume
- 将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
$ mv flume-env.sh.template flume-env.sh
$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144(这里路径替换为本机JDK安装目录)
案例实操
- 监控端口数据
案例需求:首先,Flume监控本机44444端口,然后通过telnet工具向本机44444端口发送消息,最后Flume将监听的数据实时显示在控制台。需求分析:

实现步骤:
安装telnet工具在/usr/local目录下创建flume-telnet文件夹。
$ mkdir flume-telnet再将rpm软件包(xinetd-2.3.14-40.el6.x86_64.rpm、telnet-0.17-48.el6.x86_64.rpm和telnet-server-0.17-48.el6.x86_64.rpm)拷入/usr/local/flume-telnet文件夹下面。执行RPM软件包安装命令:
$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm $ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm $ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm
判断44444端口是否被占用判断44444端口是否占用,如果被占用则kill掉或者更换端口
$ sudo netstat -tunlp | grep 44444 功能描述:netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。 基本语法:netstat [选项] 选项参数: -t或–tcp:显示TCP传输协议的连线状况; -u或–udp:显示UDP传输协议的连线状况; -n或--numeric:直接使用ip地址,而不通过域名服务器; -l或--listening:显示监控中的服务器的Socket; -p或--programs:显示正在使用Socket的程序识别码和程序名称;``
创建Flume Agent配置文件
flume-telnet-logger.conf在flume目录下创建job文件夹并进入job文件夹
$ mkdir job $ cd job/在job文件夹下创建Flume Agent配置文件
flume-telnet-logger.conf$ touch flume-telnet-logger.conf # 如果觉得vim上手难度太大,可以使用gedit来进行编辑 $ vim flume-telnet-logger.conf # 在conf文件中加入以下内容 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
注:配置文件来源于官方手册

先开启flume监听端口
$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console 参数说明: --conf conf/ :表示配置文件存储在conf/目录 --name a1 :表示给agent起名为a1 --conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。 -Dflume.root.logger<span class="token operator">==</span>INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。``
使用telnet工具向本机的44444端口发送内容
$ telnet localhost 44444将A服务器上的日志实时采集到B服务器一般跨节点都是使用
avro sink技术选型有两种方案:
exec source + memory channel + avro sink
// Flume的关键就是写配置文件,仍然是在conf文件夹下创建配置文件 // avro-memory-sink.conf Name the components on this agentexec-memory-avro.sources = exec-source exec-memory-avro.sinks = arvo-sink exec-memory-avro.channels = memory-channel Describe/configure the sourceexec-memory-avro.sources.exec-source.type = exec exec-memory-avro.sources.exec-source.command = tail -F $FLUME_HOME/logs/flume.log exec-memory-avro.sources.exec-source.shell = /bin/sh -c Describe the sinkexec-memory-avro.sinks.arvo-sink.type = avro exec-memory-avro.sinks.arvo-sink.hostname = localhost exec-memory-avro.sinks.arvo-sink.port = 44444 Use a channel which buffers events in memoryexec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.channels.memory-channel.capacity = 1000 exec-memory-avro.channels.memory-channel.transactionCapacity = 100 Bind the source and sink to the channelexec-memory-avro.sources.exec-source.channels = memory-channel exec-memory-avro.sinks.arvo-sink.channel = memory-channelavro source + memory channel + logger sink
// avro-logger-sink.conf # Name the components on this agent avro-memory-logger.sources = avro-source avro-memory-logger.sinks = logger-sink avro-memory-logger.channels = memory-channel Describe/configure the sourceavro-memory-logger.sources.avro-source.type = avro avro-memory-logger.sources.avro-source.bind = localhost avro-memory-logger.sources.avro-source.port = 44444 Describe the sinkavro-memory-logger.sinks.logger-sink.type = logger Use a channel which buffers events in memoryavro-memory-logger.channels.memory-channel.type = memory avro-memory-logger.channels.memory-channel.capacity = 1000 avro-memory-logger.channels.memory-channel.transactionCapacity = 100 Bind the source and sink to the channelavro-memory-logger.sources.avro-source.channels = memory-channel avro-memory-logger.sinks.logger-sink.channel = memory-channel
接下来启动两个配置
先启动avro-memory-logger flume-ng agent \ –name avro-memory-logger \ –conf $FLUME_HOME/conf \ –conf-file $FLUME_HOME/conf/avro-memory-logger.conf \ -Dflume.root.logger=INFO,console 再启动另外一个 flume-ng agent –name exec-memory-avro –conf $FLUME_HOME/conf \ –conf-file $FLUME_HOME/conf/exec-memory-avro.conf \ -Dflume.root.logger=INFO,console


一个可能因为手误出现的bug
log4j:WARN No appenders could be found for logger (org.apache.flume.lifecycle.LifecycleSupervisor). log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
出现这个错误是因为路径没有写对
往监听的日志中输入一段字符串,可以看到我们的logger sink 已经成功接收到信息

上面Flume的基本流程图如下

Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[3]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
具体的架构可以查看官网的intro部分。
因为在实际编程中使用kafka_2.11-0.11.00以上版本和使用以下版本的Java API 不一致,所以推荐直接参照官网的文档进行编程。
环境搭建
单机单节点
搭建说明
需要有一定的Linux操作经验,对于没有权限之类的问题要懂得通过命令解决
Kafka的安装相比Flume来说更加复杂,因为Kafka依赖于Zookeeper
环境说明:
- os:Ubuntu 18.04
- zookeeper:zookeeper 3.4.9
- kafka:kafka_2.11-0.11.0.0
- jdk:jdk 8(kafka启动需要使用到jdk)
详细说明:
一、jdk安装
jdk分为以下几种:jre、openjdk、 oracle jdk,这里我们要安装的是oracle jdk(推荐安装)
add-apt-repository ppa:webupd8team/java
apt-get update
apt-get install oracle-java8-installer
apt-get install oracle-java8-set-default
测试安装版本:
二、安装配置zookeeper单机模式
下载zookeeper 3.4.5,开始安装(软件包详见软件包下的kafka中的压缩包):
cd /usr/local
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz
等待安装成功:
解压:
tar -zxvf zookeeper-3.4.5.tar.gz
解压后同目录下便存在相同文件夹:
切换到conf目录下:
cd zookeeper-3.4.5/conf/
复制zoo_sample.cfg到zoo.cfg:
cp zoo_sample.cfg zoo.cfg
然后编辑zoo.cfg如下(其它不用管,默认即可):
initLimit=10
syncLimit=5
dataDir=/home/young/zookeeper/data
clientPort=2181
别忘了新建dataDir目录:
mkdir /home/young/zookeeper/data
为zookeeper创建环境变量,打开/etc/profile文件,并在最末尾添加如下内容:
vi /etc/profile
添加内容如下:
export ZOOKEEPER_HOME=/home/young/zookeeper
export PATH=.:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATH
配置完成之后,切换到zookeeper/bin目录下,启动服务:
关闭服务:
这里暂时先关闭zookeeper服务,防止下面使用kafka启动时报端口占用错误。
三、安装配置kafka单机模式
下载kafka(安装包详见软件包kafka下的压缩包):
cd /usr/local
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz
解压:
tar -zxvf kafka_2.11-0.11.0.0.tgz
进入kafka/config目录下:
以上文件是需要修改的文件,下面一个个修改配置:
配置server.properties:
以下为修改的,其他为默认即可:
#broker.id需改成正整数,单机为1就好
broker.id=1
#指定端口号
port=9092
#localhost这一项还有其他要修改,详细见下面说明
host.name=localhost
#指定kafka的日志目录
log.dirs=/usr/local/kafka_2.11-0.11.0.0/kafka-logs
#连接zookeeper配置项,这里指定的是单机,所以只需要配置localhost,若是实际生产环境,需要在这里添加其他ip地址和端口号
zookeeper.connect=localhost:2181
配置zookeeper.properties:
#数据目录
dataDir=/usr/local/kafka_2.11-0.11.0.0/zookeeper/data
#客户端端口
clientPort=2181
host.name=localhost
配置producer.properties:
zookeeper.connect=localhost:2181
配置consumer.properties:
zookeeper.connect=localhost:2181
最后还需要拷贝几个jar文件到kafka的libs目录,分别是zookeeper-xxxx.jar、log4j-xxxx.jar、slf4j-simple-xxxx.jar,最后如下:
四、kafka的使用
启动zookeeper服务:
bin/zookeeper-server-start.sh config/zookeeper.properties
新开一个窗口启动kafka服务:
bin/kafka-server-start.sh config/server.properties
至此单机服务搭建已经全部完成
单机多节点
对于单机单节点只需要使用一个配置文件来启动即可,那么对于单机多节点,只需要建立多个配置文件,并且启动即可。比如我们需要有三个节点。
然后我们的每个server properies里面的端口以及ID要不一致
server-1.properties

server-2.properties

server-3.properties

当然其对应的log对应目录也要修改,这个就不多说了
然后在控制台启动
> bin/kafka-server-start.sh config/server-1.properties &
> bin/kafka-server-start.sh config/server-2.properties &
> bin/kafka-server-start.sh config/server-3.properties &
通过jps -m 能看到三个kafka即可(可能以普通用户看不到相应的进程,只是因为没给到权限,可以给权限或者直接sudo su切换到超级用户)
Kafka控制台的一些命令操作
控制台中我们可以通过命令建立topic,并且开启一个消费者一个生产者来模拟通信,这些在官网的quickstart中都有详尽的描述
![[外链图片转存失败(img-cCfCODtn-1569486879029)(../%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%9C%80%E7%BB%88%E7%89%88%E6%96%87%E6%A1%A3/kafka%E5%AD%A6%E4%B9%A0/producer.png)]](https://img-blog.csdnimg.cn/20190926164415344.png)

通过我们的一个叫topic的标签,我们建立了一个生产者和一个消费者,可以明显看到消费者接收到了生产者的消息。其他比较常用的命令,比如describe等可以自行探索。
Java API控制Kafka
接下来会说一个简单的在Java中使用Kafka小例子
这里都是基于2.11_0.11.0.0.0版本以及之后的编程来说明,更低版本相应的API有些许变化,低版本中很多函数已经被替代和废除。
基本配置
- 首先在Idea中建立一个新的Maven项目,这里我们选择一个achetype:scala-archetype-simple

接下来我们把Maven文件配置好,并且auto import dependencies,这里如果没有选择auto import,我们可以在Pom.xml右键找到maven选项里面有一个reload
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.test.spark</groupId> <artifactId>spark streaming</artifactId> <version>1.0</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.7.0</scala.version> <kafka.version>0.11.0.0</kafka.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>${kafka.version}</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <configuration> <downloadSources>true</downloadSources> <buildcommands> <buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand> </buildcommands> <additionalProjectnatures> <projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature> </additionalProjectnatures> <classpathContainers> <classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer> <classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer> </classpathContainers> </configuration> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>- 因为我们使用Java编程,所以我们在main下面建立一个java文件夹,并且把整个文件夹设为source,如下图

- 因为我们使用Java编程,所以我们在main下面建立一个java文件夹,并且把整个文件夹设为source,如下图
然后我们在这个例子会涉及到几个Class,包括启动的Class,消费者,生产者,配置
代码分析
//KafkaProperties.java
package com.test.spark.kafka;
/**
Kafka常用配置文件
/
public class KafkaProperties {
public static final String ZK= “211.83.96.204:2181”;
public static final String TOPIC= “test”;
public static final String BROKER_LIST = “211.83.96.204:9092”;
public static final String GROUP_ID = “test_group1”;
}
首先看一下配置文件,为了配置能更加全局化好修改,我们直接建立一个配置文件,把可能需要的一些全局参数放进来,方便后续开发。其中有zookeeper的IP,Topic名称,服务器列表以及group_id。
// KafkaProducerClient.java
package com.test.spark.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/** Kafka 生产者 /
public class KafkaProducerClient extends Thread {
private String topic;
private Producer<String, String> producer;
public KafkaProducerClient(String topic) {
this.topic = topic;
Properties properties = new Properties();
properties.put("bootstrap.servers","localhost:9092");
//properties.put(“serializer.class”,”kafka.serializer.StringEncoder”);
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("request.required.acks","1");
producer = new KafkaProducerString, String(properties);
}
@Override
public void run() {
int messageNo = 1;
while(true) {
String message = "message_" + messageNo;
producer.send(new ProducerRecordString, String(topic, message));
System.out.println("Sent: " + message);
messageNo ++;
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
消费者中我们使用多线程的方式,循环发送消息
// KafkaConsumerClient.java
package com.test.spark.kafka;
import kafka.consumer.ConsumerConnector$class;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
/** Kafka消费者 */
public class KafkaConsumerClient {
private String topic;
public KafkaConsumerClient(String topic) {
this.topic = topic;
}
public void start() {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", KafkaProperties.GROUP_ID);//不同ID 可以同时订阅消息
props.put("enable.auto.commit", "false");//自动commit
props.put("auto.commit.interval.ms", "1000");//定时commit的周期
props.put("session.timeout.ms", "30000");//consumer活性超时时间
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumerString, String consumer = new KafkaConsumerString, String(props);
consumer.subscribe(Arrays.asList(this.topic));//订阅TOPIC
try {
while(true) {//轮询ConsumerRecordsString
String records =consumer.poll(Long.MAX_VALUE);//超时等待时间
for (TopicPartition partition : records.partitions()) {
ListConsumerRecordString, String partitionRecords = records.records(partition);
for (ConsumerRecordString, String record : partitionRecords) {
System.out.println("receive" + ": " + record.value());
}
consumer.commitSync();//同步
}
}
} finally {
consumer.close();
}
}
}
在消费中我们会轮询消息
Flume+Kafka配合
把logger sink ===> kafka sink
sink kafka: producer
所以启动一个kafka的consumer,直接对接到kafka sink消费掉即可
//avro-memory-kafka.conf
Name the components on this agentavro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
Describe/configure the sourceavro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = localhost
avro-memory-kafka.sources.avro-source.port = 44444
Describe the sinkavro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = localhost:9092
avro-memory-kafka.sinks.kafka-sink.topic = test
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
Use a channel which buffers events in memoryavro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
Bind the source and sink to the channelavro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
注意这个batchSize,在数据量没有到达设定的阈值时,他会有一个timeout,这之后才会有数据发过来
Spark
Spark 简介
- 什么是Spark?Spark作为Apache顶级的开源项目,是一个快速、通用的大规模数据处理引擎,和Hadoop的MapReduce计算框架类似,但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟。相对于“one stack to rule them all”的目标,实际上,Spark已经成为轻量级大数据快速处理的统一平台,各种不同的应用,如实时流处理、机器学习、交互式查询等,都可以通过Spark建立在不同的存储和运行系统上。
- Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
- Spark于2009年诞生于加州大学伯克利分校AMPLab。目前,已经成为Apache软件基金会旗下的顶级开源项目。相对于MapReduce上的批量计算、迭代型计算以及基于Hive的SQL查询,Spark可以带来上百倍的性能提升。目前Spark的生态系统日趋完善,Spark SQL的发布、Hive on Spark项目的启动以及大量大数据公司对Spark全栈的支持,让Spark的数据分析范式更加丰富。
Spark环境搭建
Hadoop安装(Spark依赖于Hadoop安装)
Hadoop可以通过HadoopDownloadOne 或者HadoopDownloadTwo 下载,一般选择下载最新的稳定版本,即下载 “stable” 下的hadoop-2.x.y.tar.gz 这个格式的文件(详见安装文件夹中的hadoop-2.7.7)
$ sudo tar -zxf hadoop-2.7.7.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
$ cd /usr/local/hadoop
$ ./bin/hadoop version
Hadoop单机配置及运行测试
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子(运行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
$ cd /usr/local/hadoop
$ mkdir ./input
$ cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
$ ./bin/Hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
$ cat ./output/* # 查看运行结果
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
如果中间提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然后,再次启动Hadoop。
Spark安装
此处采用Spark和Hadoop一起安装使用,这样,就可以让Spark使用HDFS存取数据。需要说明的是,当安装好Spark以后,里面就自带了scala环境,不需要额外安装scala。在安装spark之前,需要先安装Java和Hadoop。
需要的具体运行环境如下:
Ø Ubuntu16.04以上
Ø Hadoop 2.7.1以上
Ø Java JDK 1.8以上
Ø Spark 2.1.0 以上
Ø Python 3.4以上
(此次系统环境使用的Ubuntu16.04,自带Python,不需额外安装)
由于已经安装了Hadoop,所以在Choose a package type后面需要选择Pre-build with user-provided Hadoop,然后点击Download Spark后面的spark-2.1.0-bin-without-hadoop.tgz下载即可。需要说明的是,Pre-build with user-provided Hadoop:属于“Hadoop free”版,这样下载到的Spark,可应用到任意Hadoop版本。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
这里介绍Local模式(单机模式)的 Spark安装。我们选择Spark 2.4.3版本,并且假设当前使用用户名hadoop登录了Linux操作系统。
$ sudo tar -zxf ~/下载/spark-2.4.3-bin-without-hadoop.tgz -C/usr/local/
$ sudo mv ./spark-2.4.3-bin-without-hadoop/ ./spark
$ sudo chown -R hadoop:hadoop ./spark # 此处的 hadoop 为你的用户名
安装后,还需要修改Spark的配置文件spark-env.sh
$ cd /usr/local/spark
$ sudo cp conf/spark-env.sh.template conf/spark-env.sh
$ sudo vim conf/spark-env.sh
#添加下面的环境变量信息
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop:classpath)
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。通过运行Spark自带的示例,验证Spark是否安装成功。
$ cd /usr/local/spark
$ bin/run-example SparkPi
过滤后的运行结果如下图示,可以得到π 的 5 位小数近似值:

Spark不依赖Hadoop安装
Spark同样也可以不依赖hadoop进行安装,但是仍然需要JDK环境,同样是在Spark官网上,选择spark-2.4.3-bin-hadoop2.7.tgz。我们直接将其解压出来,下面我们开始配置环境变量。我们进入编辑/etc/profile,在最后加上如下代码。
#Spark
export SPARK_HOME=/opt/spark-2.4.3
export PATH=$PATH:$SPARK_HOME/bin
然后进入/spark-2.3.1/bin目录下即可直接运行spark-shell。
下面配置本地集群环境,首先我们进入刚刚解压的Spark目录,进入/spark-2.2.1/conf/,拷贝一份spark-env.sh。
$ cp spark-env.sh.template spark-env.sh
然后我们编辑这个文件,添加如下环境设置(按自身环境修改)
#export SCALA_HOME=/opt/scala-2.13.0
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64 #这里是你jdk的安装路径
export SPARK_HOME=/opt/spark-2.4.3
export SPARK_MASTER_IP=XXX.XX.XX.XXX #将这里的xxx改为自己的Linux的ip地址
#export SPARK_EXECUTOR_MEMORY=512M
#export SPARK_WORKER_MEMORY=1G
#export master=spark://XXX.XX.XX.XXX:7070
再回到conf目录下,拷贝一份slaves。
$ cp slaves.template slaves
在slaves最后加上localhost,保存即可。最后想要启动spark,进入安装目录下的sbin文件夹下,运行start-all.sh输入登录密码,master和worker进程就能按照配置文件启动。
在Spark Shell 中运行代码
这里介绍Spark Shell的基本使用。Spark shell提供了简单的方式来学习API,并且提供了交互的方式来分析数据。它属于REPL(Read-Eval-Print Loop,交互式解释器),提供了交互式执行环境,表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改,这样可以在很大程度上提升开发效率。
Spark Shell支持Scala和Python,本文使用 Scala 来进行介绍。前面已经安装了Hadoop和Spark,如果Spark不使用HDFS和YARN,那么就不用启动Hadoop也可以正常使用Spark。如果在使用Spark的过程中需要用到 HDFS,就要首先启动 Hadoop。
这里假设不需要用到HDFS,因此,就没有启动Hadoop。现在直接开始使用Spark。Spark-shell命令及其常用的参数如下:
$ ./bin/spark-shell —master
Spark的运行模式取决于传递给SparkContext的Master URL的值。Master URL可以是以下任一种形式:
- local 使用一个Worker线程本地化运行SPARK(完全不并行)
- local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
- local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
- spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077.
- yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到。
- yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到。
- mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050。
需要强调的是,本文采用“本地模式”(local)运行Spark,关于如何在集群模式下运行Spark,之后的文章会着重介绍。
在Spark中采用本地模式启动Spark Shell的命令主要包含以下参数:
–master:这个参数表示当前的Spark Shell要连接到哪个master,如果是local[*],就是使用本地模式启动spark-shell,其中,中括号内的星号表示需要使用几个CPU核心(core);
–jars: 这个参数用于把相关的JAR包添加到CLASSPATH中;如果有多个jar包,可以使用逗号分隔符连接它们;
比如,要采用本地模式,在4个CPU核心上运行spark-shell:
$ cd /usr/local/spark
$ /bin/spark-shell —master local[4]
或者,可以在CLASSPATH中添加code.jar,命令如下:
$ cd /usr/local/spark
$ ./bin/spark-shell -master local[4] --jars code.jar
可以执行spark-shell –help命令,获取完整的选项列表,具体如下:
$ cd /usr/local/spark
$ ./bin/spark-shell —help
[外链图片转存失败(img-36hzRWo9-1569486879033)(spark-shell.png)]
上面是命令使用方法介绍,下面正式使用命令进入spark-shell环境,可以通过下面命令启动spark-shell环境:
scala> 8*2+5
res0: Int = 21
最后,可以使用命令“:quit”退出Spark Shell,如下所示:
scala>:quit
或者,也可以直接使用“Ctrl+D”组合键,退出Spark Shell
Scala编写wordCount
任务需求
学会了上文基本的安装和执行后,现在练习一个任务:编写一个Spark应用程序,对某个文件中的单词进行词频统计。
准备工作:进入Linux系统,打开“终端”,进入Shell命令提示符状态,然后,执行如下命令新建目录:
$ cd /usr/local/spark
$ mkdir mycode
$ cd mycode
$ mkdir wordcount
$ cd wordcount
然后,在/usr/local/spark/mycode/wordcount目录下新建一个包含了一些语句的文本文件word.txt,命令如下:
$ vim word.txt
首先可以在文本文件中随意输入一些单词,用空格隔开,编写Spark程序对该文件进行单词词频统计。然后,按键盘Esc键退出vim编辑状态,输入“:wq”保存文件并退出vim编辑器。
在Spark-Shell中执行词频统计
- 启动Spark-Shell首先,登录Linux系统(要注意记住登录采用的用户名,本教程统一采用hadoop用户名进行登录),打开“终端”(可以在Linux系统中使用Ctrl+Alt+T组合键开启终端),进入shell命令提示符状态,然后执行以下命令进入spark-shell:
$ cd /usr/local/spark
$ ./bin_spark-shell
$ …这里省略启动过程显示的一大堆信息
$ scala>
启动进入spark-shell需要一点时间,在进入spark-shell后,我们可能还需要到Linux文件系统中对相关目录下的文件进行编辑和操作(比如要查看spark程序执行过程生成的文件),这个无法在park-shell中完成,因此,这里再打开第二个终端,用来在Linux系统的Shell命令提示符下操作。
加载本地文件在开始具体词频统计代码之前,需要考虑如何加载文件,文件可能位于本地文件系统中,也有可能存放在分布式文件系统HDFS中,下面先介绍介绍如何加载本地文件,以及如何加载HDFS中的文件。首先,请在第二个终端窗口下操作,用下面命令到达
/usr/local/spark/mycode/wordcount目录,查看一下上面已经建好的word.txt的内容:
$ cd /usr/local/spark/mycode/wordcount $ cat word.txtCat命令会把word.txt文件的内容全部显示到屏幕上。
现在切换回spark-shell,然后输入下面命令:
scala> val textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”)上面代码中,val后面的是变量textFile,而sc.textFile()中的这个textFile是sc的一个方法名称,这个方法用来加载文件数据。这两个textFile不是一个东西,不要混淆。实际上,val后面的是变量textFile,你完全可以换个变量名称,比如,val lines = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”)。这里使用相同名称,就是有意强调二者的区别。
注意要加载本地文件,必须采用“file:///”开头的这种格式。执行上上面这条命令以后,并不会马上显示结果,因为Spark采用惰性机制,只有遇到“行动”类型的操作,才会从头到尾执行所有操作。所以,下面我们执行一条“行动”类型的语句,就可以看到结果:
scala>textFile.first()first()是一个“行动”(Action)类型的操作,会启动真正的计算过程,从文件中加载数据到变量textFile中,并取出第一行文本。屏幕上会显示很多反馈信息,这里不再给出,你可以从这些结果信息中,找到word.txt文件中的第一行的内容。
正因为Spark采用了惰性机制,在执行转换操作的时候,即使我们输入了错误的语句,spark-shell也不会马上报错,而是等到执行“行动”类型的语句时启动真正的计算,那个时候“转换”操作语句中的错误就会显示出来,比如:
val textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word123.txt”)上面我们使用了一个根本就不存在的word123.txt,执行上面语句时,spark-shell根本不会报错,因为,没有遇到“行动”类型的first()操作之前,这个加载操作时不会真正执行的。然后,我们执行一个“行动”类型的操作first(),如下:
scala> textFile.first()执行上面语句后,会返回错误信息“拒绝连接”,因为这个word123.txt文件根本就不存在。现在我们可以练习一下如何把textFile变量中的内容再次写回到另外一个文本文件wordback.txt中:
val textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”) textFile.saveAsTextFile(“file:///usr/local/spark/mycode/wordcount/writeback”)上面的saveAsTextFile()括号里面的参数是保存文件的路径,不是文件名。saveAsTextFile()是一个“行动”(Action)类型的操作,所以马上会执行真正的计算过程,从word.txt中加载数据到变量textFile中,然后,又把textFile中的数据写回到本地文件目录“_usr_local_spark_mycode_wordcount_writeback/”下面,现在让我们切换到Linux Shell命令提示符窗口中,执行下面命令:
$ cd /usr/local/spark/mycode/wordcount/writeback/ $ ls执行结果会显示,有两个文件part-00000和_SUCCESS,我们可以使用cat命令查看一下part-00000文件,会发现结果是和上面word.txt中的内容一样的。
词频统计
有了前面的铺垫性介绍,下面我们开始第一个Spark应用程序:WordCount。请切换到spark-shell窗口,输入如下命令:
scala> val textFile = sc.textFile(“file:///usr/local/spark/mycode/wordcount/word.txt”) scala> val wordCount = textFile.flatMap(line => line.split(“ “)).map(word => (word, 1)).reduceByKey((a, b) => a + b) scala> wordCount.collect()上面只给出了代码,省略了执行过程中返回的结果信息,因为返回信息很多。下面简单解释一下上面的语句。
- textFile包含了多行文本内容,textFile.flatMap(line => line.split(” “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line => line.split(” “)。line => line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” “),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
- 然后,针对这个大的单词集合,执行map()操作,也就是map(word => (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word => (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
- 程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey((a, b) => a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:(a, b) => a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
编写独立应用程序执行词频统计
在上面spark-shell编写wordcount后,下面我们编写一个Scala应用程序来实现词频统计。首先登录Linux系统,进入Shell命令提示符状态,然后执行下面命令:
$ cd /usr/local/spark/mycode/wordcount/
$ mkdir -p src/main/scala 这里加入-p选项,可以一起创建src目录及其子目录
然后在“/usr/local/spark/mycode/wordcount/src/main/scala”目录下新建一个test.scala文件,里面包含如下代码:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext./
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = “file:///usr/local/spark/mycode/wordcount/word.txt”
val conf = new SparkConf().setAppName(“WordCount”).setMaster(“local[2]”)
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(“ “)).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}
注意,SparkConf().setAppName(“WordCount”).setMaster(“local[2]”)这句语句,也可以删除.setMaster(“local[2]”),只保留 val conf = new SparkConf().setAppName(“WordCount”)。
如果test.scala没有调用SparkAPI,则只要使用scalac命令编译后执行即可。此处test.scala程序依赖 Spark API,因此需要通过 sbt 进行编译打包。首先执行如下命令:
$ cd /usr/local/spark/mycode/wordcount/
$ vim simple.sbt
通过上面代码,新建一个simple.sbt文件,请在该文件中输入下面代码:
name := “Simple Project”
version := “1.0”
scalaVersion := “2.11.8”
libraryDependencies += “org.apache.spark” %% “spark-core” % “2.1.0”
下面我们使用sbt打包Scala程序。为保证sbt能正常运行,先执行如下命令检查整个应用程序的文件结构,应该是类似下面的文件结构:
$ ./src
$ ./src/main
$ ./src/main/scala
$ ./src/main/scala/test.scala
$ ./simple.sbt
$ ./word.txt
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
$ cd /usr/local/spark/mycode/wordcount/ 请一定把这目录设置为当前目录
$ /usr/local/sbt/sbt package
上面执行过程需要消耗几分钟时间,屏幕上会返回一下信息:
hadoop@dblab-VirtualBox:_usr_local_spark_mycode_wordcount$ /usr_local_sbt_sbt package
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0
[info] Set current project to Simple Project (in build file:/usr_local_spark_mycode_wordcount/)
[info] Updating {file:/usr_local_spark_mycode_wordcount/}wordcount…
[info] Resolving jline#jline;2.12.1 …
[info] Done updating.
[info] Packaging _usr_local_spark_mycode_wordcount_target_scala-2.11_simple-project_2.11-1.0.jar …
[info] Done packaging.
[success] Total time: 34 s, completed 2017-2-20 10:13:13
若屏幕上返回上述信息表明打包成功,生成的 jar 包的位置为/usr/local/spark/mycode/wordcount/target/scala-2.11_simple-project_2.11-1.0.jar。
最后通过spark-submit 运行程序。我们就可以将生成的jar包通过spark-submit提交到Spark中运行了,命令如下:
$ /usr/local/spark/bin/spark-submit —class “WordCount” /usr/local/spark/mycode/wordcount/target/scala-2.11_simple-project_2.11-1.0.jar
最终得到的词频统计结果类似如下:
(Spark,1)
(is,1)
(than,1)
(fast,1)
(love,2)
(i,1)
(I,1)
(hadoop,2)
Flume_Kafka_SparkStreaming实现词频统计
准备工作
在做这个project之前,需要预先准备好的环境如下:
安装kafka(参考第一节)、安装flume(参考第二节)、安装Spark(参考第三节) 。
做完上面三个工作之后,我们开始进入正式的词频统计Demo。
Spark准备工作
要通过Kafka连接Spark来进行Spark Streaming操作,Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。也就是说Spark需要jar包让Kafka和Spark streaming相连。按照我们前面安装好的Spark版本,这些jar包都不在里面,为了证明这一点,我们现在可以测试一下。请打开一个新的终端,输入以下命令启动spark-shell:
$ cd /usr/local/spark
$ ./bin/spark-shell
启动成功后,在spark-shell中执行下面import语句:
import org.apache.spark.streaming.kafka._
程序报错,因为找不到相关jar包。根据Spark官网的说明,对于Spark版本,如果要使用Kafka,则需要下载spark-streaming-kafka相关jar包。Jar包下载地址(注意版本对应关系)。

接下来需要把这个文件复制到Spark目录的jars目录下,输入以下命令:
$ cd /usr/local/spark/jars
$ mkdir kafka
$ cp ./spark-streaming-kafka-0-8_2.11-2.1.0.jar /usr/local/spark/jars/kafka
下面把Kafka安装目录的libs目录下的所有jar文件复制到/usr/local/spark/jars/kafka目录下输入以下命令:至此,所有环境准备工作已全部完成,下面开始编写代码。
Project 过程
编写Flume配置文件flume_to_kafka.conf输入命令:
$ cd /usr/local/kafka/libs $ ls $ cp ./* /usr/local/spark/jars/kafka内容如下:
a1.sources=r1 a1.channels=c1 a1.sinks=k1 #Describe/configure the source a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=33333 #Describe the sink a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic=test a1.sinks.k1.kafka.bootstrap.servers=localhost:9092 a1.sinks.k1.kafka.producer.acks=1 a1.sinks.k1.flumeBatchSize=20 #Use a channel which buffers events in memory a1.channels.c1.type=memory a1.channels.c1.capacity=1000000 a1.channels.c1.transactionCapacity=1000000 #Bind the source and sink to the channel a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1编写Spark Streaming程序(进行词频统计的程序)首先创建scala代码的目录结构,输入命令:
$ cd /usr/local/spark/mycode $ mkdir flume_to_kafka $ cd flume_to_kafka $ mkdir -p src/main/scala $ cd src/main/scala $ vim KafkaWordCounter.scalaKafkaWordCounter.scala是用于单词词频统计,它会把从kafka发送过来的单词进行词频统计,代码内容如下:
reduceByKeyAndWindow函数作用解释如下:
package org.apache.spark.examples.streaming import org.apache.spark._ import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.streaming.kafka.KafkaUtils object KafkaWordCounter{ def main(args:Array[String]){ StreamingExamples.setStreamingLogLevels() val sc=new SparkConf().setAppName("KafkaWordCounter").setMaster("local[2]") val ssc=new StreamingContext(sc,Seconds(10)) ssc.checkpoint("file:///usr/local/spark/mycode/flume_to_kafka/checkpoint") //设置检查点 val zkQuorum="localhost:2181" //Zookeeper服务器地址 val group="1" //topic所在的group,可以设置为自己想要的名称,比如不用1,而是val group = "test-consumer-group" val topics="test" //topics的名称 val numThreads=1 //每个topic的分区数 val topicMap=topics.split(",").map((_,numThreads.toInt)).toMap val lineMap=KafkaUtils.createStream(ssc,zkQuorum,group,topicMap) val lines=lineMap.map(_._2) val words=lines.flatMap(_.split(" ")) val pair=words.map(x => (x,1)) val wordCounts=pair.reduceByKeyAndWindow(_ + _,_ - _,Minutes(2),Seconds(10),2) wordCounts.print ssc.start ssc.awaitTermination } }reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
此代码中就是一个窗口转换操作reduceByKeyAndWindow,其中,Minutes(2)是滑动窗口长度,Seconds(10)是滑动窗口时间间隔(每隔多长时间滑动一次窗口)。reduceByKeyAndWindow中就使用了加法和减法这两个reduce函数,加法和减法这两种reduce函数都是“可逆的reduce函数”,也就是说,当滑动窗口到达一个新的位置时,原来之前被窗口框住的部分数据离开了窗口,又有新的数据被窗口框住,但是,这时计算窗口内单词的词频时,不需要对当前窗口内的所有单词全部重新执行统计,而是只要把窗口内新增进来的元素,增量加入到统计结果中,把离开窗口的元素从统计结果中减去,这样,就大大提高了统计的效率。尤其对于窗口长度较大时,这种“逆函数”带来的效率的提高是很明显的。
创建StreamingExamples.scala继续在当前目录(/usr/local/spark/mycode/flume_to_kafka/src/main/scala)下创建StreamingExamples.scala代码文件,用于设置log4j,输入命令:
vim StreamingExamples.scala
package org.apache.spark.examples.streaming import org.apache.spark.internal.Logging import org.apache.log4j.{Level, Logger} //Utility functions for Spark Streaming examples. object StreamingExamples extends Logging { //Set reasonable logging levels for streaming if the user has not configured log4j. def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { // We first log something to initialize Spark's default logging, then we override the // logging level. logInfo("Setting log level to [WARN] for streaming example." +" To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }创建StreamingExamples.scala继续在当前目录(/usr/local/spark/mycode/flume_to_kafka/src/main/scala)下创建StreamingExamples.scala代码文件,用于设置log4j,输入命令:
vim StreamingExamples.scala
package org.apache.spark.examples.streaming import org.apache.spark.internal.Logging import org.apache.log4j.{Level, Logger} //Utility functions for Spark Streaming examples. object StreamingExamples extends Logging { //Set reasonable logging levels for streaming if the user has not configured log4j. def setStreamingLogLevels() { val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements if (!log4jInitialized) { // We first log something to initialize Spark's default logging, then we override the // logging level. logInfo("Setting log level to [WARN] for streaming example." +" To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }打包文件simple.sbt输入命令:
$ cd /usr/local/spark/mycode/flume_to_kafka $ vim simple.sbt内容如下:
name := "Simple Project" version := "1.0" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0" libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.1.0" libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-8_2.11" % "2.1.0"要注意版本号一定要设置正确,在/usr/local/spark/mycode/flume_to_kafka目录下输入命令:
$ cd /usr/local/spark/mycode/flume_to_kafka $ find .打包之前,这条命令用来查看代码结构,目录结构如下所示:

- 打包编译
一定要在/usr/local/spark/mycode/flume_to_kafka目录下运行打包命令。
输入命令:
$ cd /usr/local/spark/mycode/flume_to_kafka
$ /usr/local/sbt/sbt package
第一次打包的过程可能会很慢,请耐心等待几分钟。打包成功后,会看到SUCCESS的提示。
- 启动zookeeper和kafka
#启动zookeeper:
$ cd /usr/local/kafka
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties
# 新开一个终端,启动Kafka:
$ cd /usr/local/kafka
$ bin/kafka-server-start.sh config/server.properties
- 运行程序KafkaWordCounter
打开一个新的终端,我们已经创建过topic,名为test(这是之前在flume_to_kafka.conf中设置的topic名字),端口号2181。在终端运行KafkaWordCounter程序,进行词频统计,由于现在没有启动输入,所以只有提示信息,没有结果。
输入命令:
$ cd /usr/local/spark
$/usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCounter" /usr/local/spark/mycode/flume_to_kafka/target/scala-2.11/simple-project_2.11-1.0.jar
其中”/usr/local/spark/jars/“和”/usr/local/spark/jars/kafka/”用来指明引用的jar包,“org.apache.spark.examples.streaming.KafkaWordCounter”代表包名和类名,这是编写KafkaWordCounter.scala里面的包名和类名,最后一个参数用来说明打包文件的位置。
执行该命令后,屏幕上会显示程序运行的相关信息,并会每隔10秒钟刷新一次信息,用来输出词频统计的结果,此时还只有提示信息,如下所示:
[外链图片转存失败(img-ZnMkMxIN-1569486879035)(result_one.png)]
在启动Flume之前,Zookeeper和Kafka要先启动成功,不然启动Flume会报连不上Kafka的错误。
- 启动flume agent
打开第四个终端,在这个新的终端中启动Flume Agent
输入命令:
$ cd /usr/local/flume
$ bin/flume-ng agent --conf ./conf --conf-file ./conf/flume_to_kafka.conf --name a1 -Dflume.root.logger=INFO,console
启动agent以后,该agent就会一直监听localhost的33333端口,这样,我们下面就可以通过“telnet localhost 33333”命令向Flume Source发送消息。这个终端也不要关闭,让它一直处于监听状态。
- 发送消息
打开第五个终端,发送消息。输入命令:
$ telnet localhost 33333
这个端口33333是在flume conf文件中设置的source
在这个窗口里面随便敲入若干个字符和若干个回车,这些消息都会被Flume监听到,Flume把消息采集到以后汇集到Sink,然后由Sink发送给Kafka的topic(test)。因为spark Streaming程序不断地在监控topic,在输入终端和前面运行词频统计程序那个终端窗口内看到统计结果。
分布式环境搭建及相关DEMO
Flume
Flume在分布式环境下跟单机下一致,只需要在一台机器上搭建即可。
Kafka
搭建高吞吐量Kafka分布式发布订阅消息集群
- Zookeeper集群: 121.48.163.195:2181 , 113.54.154.68:2181,113.54.159.232:2181
- kafka 集群: 121.48.163.195 , 113.54.154.68,113.54.159.232
搭建 kafka 集群
kafka 集群: 121.48.163.195 , 113.54.154.68,113.54.159.232
下载kafka和zookeeper步骤和前面单机版一致
修改配置
$ vim /usr/local/kafka_2.12-0.11.0.0/config/server.properties 设置broker.id 第一台为broker.id = 0 第二台为broker.id = 1 第三台为broker.id = 2 注意这个broker.id每台服务器不能重复 然后设置zookeeper的集群地址 zookeeper.connect=121.48.163.195:2181 , 113.54.154.68:2181,113.54.159.232:2181修改zookeeper配置文件
$ vim /usr/local/zookeeper-3.4.5/conf/zoo.cfg #添加server.1 server.2 server.3 server.1=121.48.163.195:2888:3888 server.2=113.54.154.68:2888:3888 server.3=113.54.159.232:2888:3888 #添加id $ sudo echo “1” > /usr/local/zookeeper-3.4.5/data/myid(每台机器的id可以和brokerid保持一致)启动服务
# 每台机器运行命令,但是在实际大型集群中可以使用脚本的方式一键启动 $ bin/kafka-server-start.sh config/server.properties &创建主题
$ /usr/local/kafka_2.12-0.11.0.0/bin/kafka-topics.sh --create --zookeeper 121.48.163.195:2181 , 113.54.154.68:2181,113.54.159.232:2181 --replication-factor 2 --partitions 1 --topic ymq –replication-factor 2 #复制两份 –partitions 1 #创建1个分区 –topic #主题为ymq # 运行list topic命令,可以看到该主题: $ /usr/local/kafka_2.12-0.11.0.0/bin/kafka-topics.sh –list –zookeeper 121.48.163.195:2181 , 113.54.154.68:2181,113.54.159.232:2181其它操作其它操作基本语法差不多一致,不再赘述,详情可以参考官网
Kafka ManagerYahoo开源Kafka集群管理器Kafka Manager
Spark
选取三台服务器
- 121.48.163.195 主节点
- 113.54.154.68 从节点
- 113.54.159.232 从节点
设置三台服务器root用户,之后操作都用root用户进行,便于管理
修改hosts文件
$ sudo vim /etc/hosts # 在上面加上服务器ip 121.48.163.195 Master 113.54.154.68 Slave1 113.54.159.232 Slave2修改完之后
source /etc/hostsSSH无密码验证配置
安装和启动ssh协议我们需要两个服务:ssh和rsync。可以通过下面命令查看是否已经安装:
rpm -qa|grep openssh rpm -qa|grep rsync 如果没有安装ssh和rsync,可以通过下面命令进行安装: sudo apt install ssh (安装ssh协议) sudo apt install rsync (rsync是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件) service sshd restart (启动服务)配置Master无密码登录所有Slave配置Master节点,以下是在Master节点的配置操作。
- 在Master节点上生成密码对,在Master节点上执行以下命令:
ssh-keygen -t rsa -P ‘’
生成的密钥对:id_rsa和id_rsa.pub,默认存储在”/root/.ssh”目录下。
- 接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub » ~/.ssh/authorized_keys
修改ssh配置文件"/etc/ssh/sshd_config"的下列内容,将以下内容的注释去掉,在三台机器上均进行修改:
RSAAuthentication yes # 启用 RSA 认证 PubkeyAuthentication yes # 启用公钥私钥配对认证方式 AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)重启ssh服务,才能使刚才设置有效。service sshd restart
验证无密码登录本机是否成功ssh localhost
接下来的就是把公钥复制到所有的Slave机器上。使用下面的命令进行复制公钥:
$ scp /root/.ssh/id_rsa.pub root@Slave1:/root/ $ scp /root/.ssh/id_rsa.pub root@Slave2:/root/
接着配置Slave节点,以下是在Slave1节点的配置操作。
1>在”/root/“下创建”.ssh”文件夹,如果已经存在就不需要创建了。
mkdir /root/.ssh
2)将Master的公钥追加到Slave1的授权文件”authorized_keys”中去。
cat /root/id_rsa.pub » /root/.ssh/authorized_keys
3)修改”/etc/ssh/sshd_config”,具体步骤参考前面Master设置的第3步和第4步。
4)用Master使用ssh无密码登录Slave1
ssh 114.55.246.77
5)把”/root/“目录下的”id_rsa.pub”文件删除掉。
rm –r /root/id_rsa.pub
重复上面的5个步骤把Slave2服务器进行相同的配置。
配置Slave无密码登录Master以下是在Slave1节点的配置操作。
1)创建”Slave1”自己的公钥和私钥,并把自己的公钥追加到”authorized_keys”文件中,执行下面命令:
ssh-keygen -t rsa -P ‘’
cat /root/.ssh/id_rsa.pub » /root/.ssh/authorized_keys
2)将Slave1节点的公钥”id_rsa.pub”复制到Master节点的”/root/“目录下。
scp /root/.ssh/id_rsa.pub root@Master:/root/
以下是在Master节点的配置操作。
1)将Slave1的公钥追加到Master的授权文件”authorized_keys”中去。
cat ~/id_rsa.pub » ~/.ssh/authorized_keys
2)删除Slave1复制过来的”id_rsa.pub”文件。
rm –r /root/id_rsa.pub
配置完成后测试从Slave1到Master无密码登录。
ssh 114.55.246.88
按照上面的步骤把Slave2和Master之间建立起无密码登录。这样,Master能无密码验证登录每个Slave,每个Slave也能无密码验证登录到Master。
安装基础环境(JAVA和SCALA环境)这里不再赘述
Hadoop2.7.3完全分布式搭建以下是在Master节点操作:
下载二进制包hadoop-2.7.7.tar.gz
解压并移动到相应目录,我习惯将软件放到/opt目录下,命令如下:
$ tar -zxvf hadoop-2.7.3.tar.gz $ mv hadoop-2.7.7 /opt修改对应的配置文件,修改/etc/profile,增加如下内容:
export HADOOP_HOME=/opt/hadoop-2.7.3/ export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_ROOT_LOGGER=INFO,console export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"修改完成后执行
$ source /etc/profile修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh,修改JAVA_HOME 如下:
export JAVA_HOME=/usr/local/jdk1.8.0_121修改$HADOOP_HOME/etc/hadoop/slaves,将原来的localhost删除,改成如下内容:
- Slave1
- Slave2
修改$HADOOP_HOME/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.7.7/tmp</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop-2.7.7/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop-2.7.7/hdfs/data</value> </property> </configuration>cp mapred-site.xml.template mapred-site.xml,并修改$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:19888</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>Master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>Master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>Master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>Master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>Master:8088</value> </property> </configuration>复制Master节点的hadoop文件夹到Slave1和Slave2上
$ scp -r /opt/hadoop-2.7.7 root@Slave1:/opt $ scp -r /opt/hadoop-2.7.7 root@Slave2:/opt- 在Slave1和Slave2上分别修改/etc/profile,过程同Master一样
- 在Master节点启动集群,启动之前格式化一下namenode:
- Hadoop namenode -format
- 启动:
/opt/hadoop-2.7.7/sbin/start-all.sh - 至此hadoop的完全分布式搭建完毕
- 查看集群是否启动成功:
$ jps -m Master显示: SecondaryNameNode ResourceManager NameNode Slave显示: NodeManager DataNodeSpark完全分布式环境搭建以下操作都在Master节点进行。
下载二进制包spark-2.4.3-bin-hadoop2.7.tgz
解压并移动到相应目录,命令如下:
$ tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz $ mv hadoop-2.7.3 /opt修改相应的配置文件,修改/etc/profie,增加如下内容:
export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7/ export PATH=$PATH:$SPARK_HOME/bin复制spark-env.sh.template成spark-env.sh
$ cp spark-env.sh.template spark-env.sh修改$SPARK_HOME/conf/spark-env.sh,添加如下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_121 export SCALA_HOME=/usr/share/scala export HADOOP_HOME=/opt/hadoop-2.7.3 export HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop export SPARK_MASTER_IP=114.55.246.88 export SPARK_MASTER_HOST=114.55.246.88 export SPARK_LOCAL_IP=114.55.246.88 export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_CORES=2 export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7 export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)复制slaves.template成slaves
$ cp slaves.template slaves修改$SPARK_HOME/conf/slaves,添加如下内容:
Master Slave1 Slave2将配置好的spark文件复制到Slave1和Slave2节点
$ scp /opt/spark-2.4.3-bin-hadoop2.7 root@Slave1:/opt $ scp /opt/spark-2.4.3-bin-hadoop2.7 root@Slave2:/opt修改Slave1和Slave2配置在Slave1和Slave2上分别修改/etc/profile,增加Spark的配置,过程同Master一样。
在Slave1和Slave2修改$SPARK_HOME/conf/spark-env.sh,将export SPARK_LOCAL_IP=114.55.246.88改成Slave1和Slave2对应节点的IP。
在Master节点启动集群
/opt/spark-2.4.3-bin-hadoop2.7/sbin/start-all.sh查看集群是否启动成功
$ jps -m Master在Hadoop的基础上新增了: Master Slave在Hadoop的基础上新增了: Worker
在我的博客查看更多